 VLA-Adapter: An Effective Paradigm for
VLA-Adapter: An Effective Paradigm for
Background. Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by
pre-training a large-scale vision-language model on robotic data. While this approach greatly enhances performance,
it also incurs significant training costs.
An Intuitive idea. Can efficiency be improved while maintaining performance simply by reducing the backbone? We illustrate this using the recent SOTA OpenVLA-OFT method. Here, we compare OpenVLA-7B+OFT, Prismatic-VLMs (LLaMA2-7B)+OFT, and Prismatic-VLMs (Qwen2.5-0.5B)+OFT. The results are shown in Table 1. So, an effective paradigm for bridging VL to A is necessary to reduce the backbone scale while maintaining performance!

In this work. We investigate how to effectively bridge vision-language (VL) representations to action (A) space.
And then, we introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale
vision-language models and extensive pre-training.
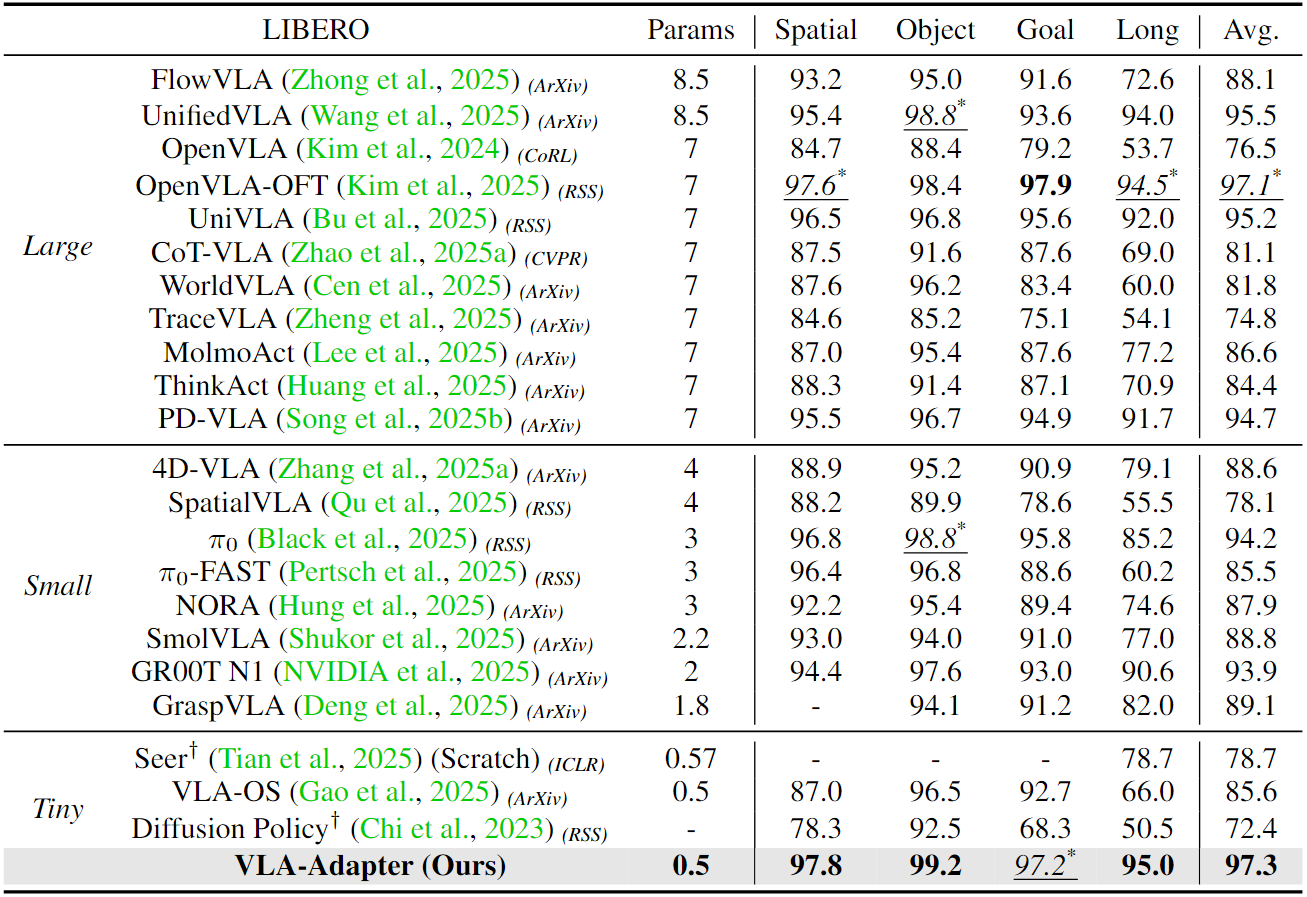
Performance. VLA-Adapter not only achieves state-of-the-art performance using only a 0.5B-parameter backbone, but also offers the fast inference speed reported to date. Furthermore, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, significantly lowering the barrier to deploying the VLA models.
Brief Description. This Vision-Language Model (VLM) follows the Prismatic-VLMs architecture. We employ each-layer Raw features (vision and language representations in VLM) and ActionQuery (additional learnable tokens) features are integrated in Bridge Attention with the corresponding-layer action latent. The degree of Raw features injection is learnable, ensuring the performance and stability of training. The layer number of the Policy network is the same as the VLM's. The Policy parameters are only 97M (Million) when the backbone is Qwen2.5-0.5B .
- Question 1.1. Which Layer of Features within The VLM Is More Effective for The Policy Network?
- Question 1.2. Are The ActionQuery Features a Better Choice Than The Raw Features?
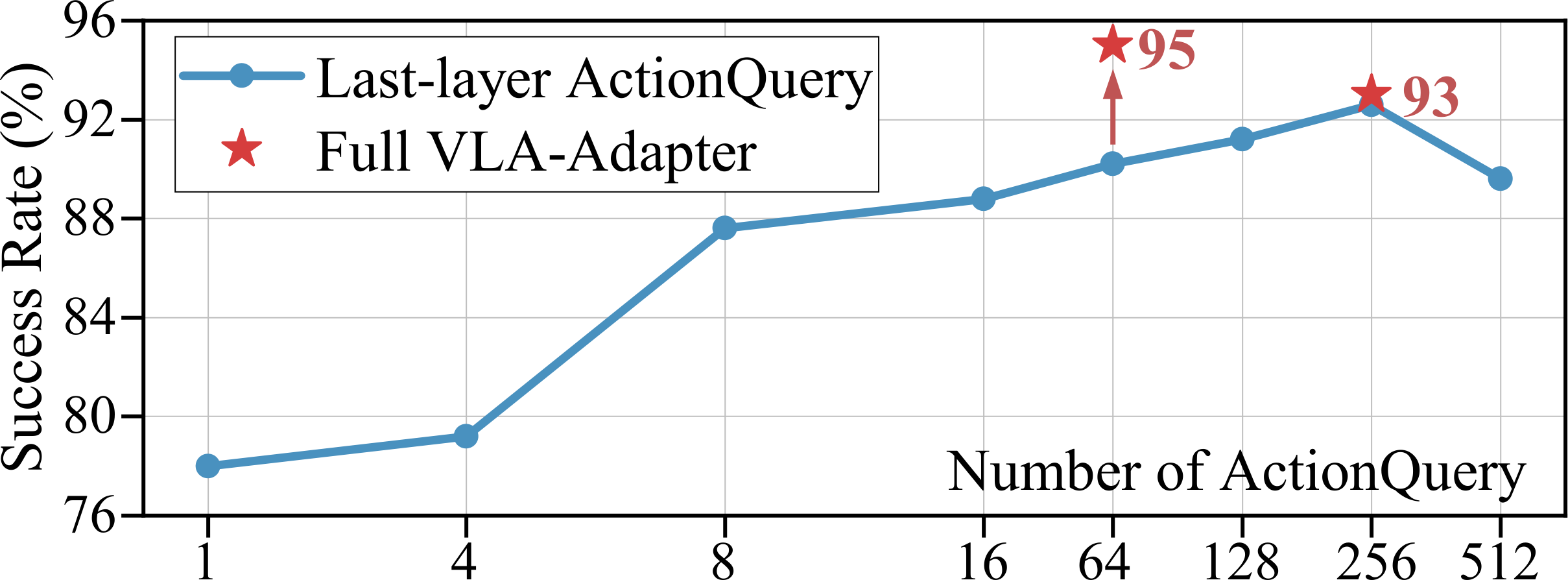
- Question 1.3. How Many ActionQueries Are Enough?
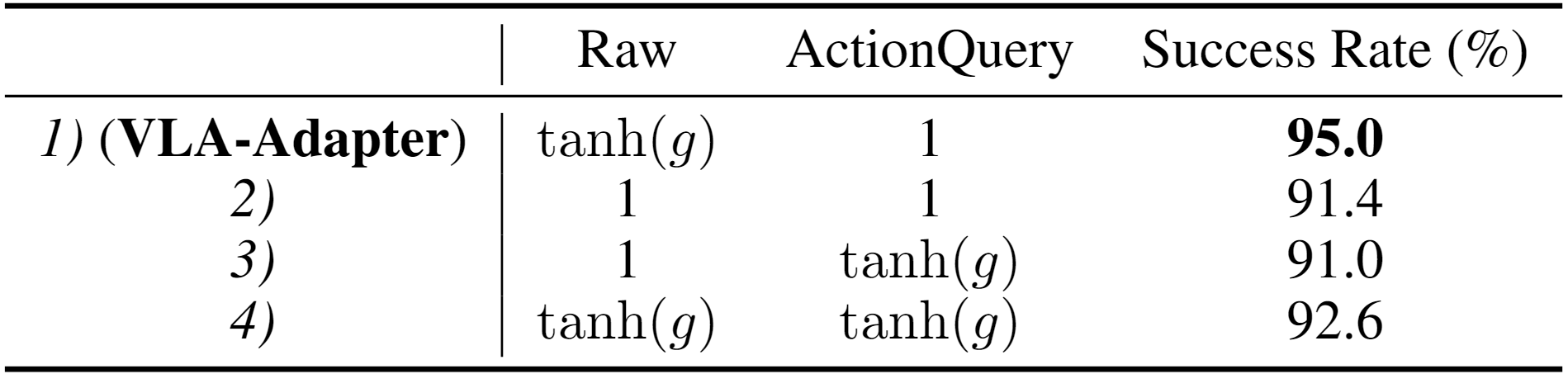
- Question 1.4. How Policy Can Better Leverage The Conditions from VLM?
· Key Finding 1. Regarding Raw features, the middle-layer latent performs better than the deep-layer latent. Deep-layer Raw features is biased towards semantic information and less effective in action generation. The middle-layer Raw features effectively integrates image and text information, retains richer multimodal details, and facilitates action generation.
· Key Finding 2. Regarding ActionQuery features, deep-layer latent performs better than other-layer latent. Since ActionQuery is trained from scratch, and deep-layer ActionQuery features aggregates richer multimodal details and is more effectively promoting action generation than the shallow layers.
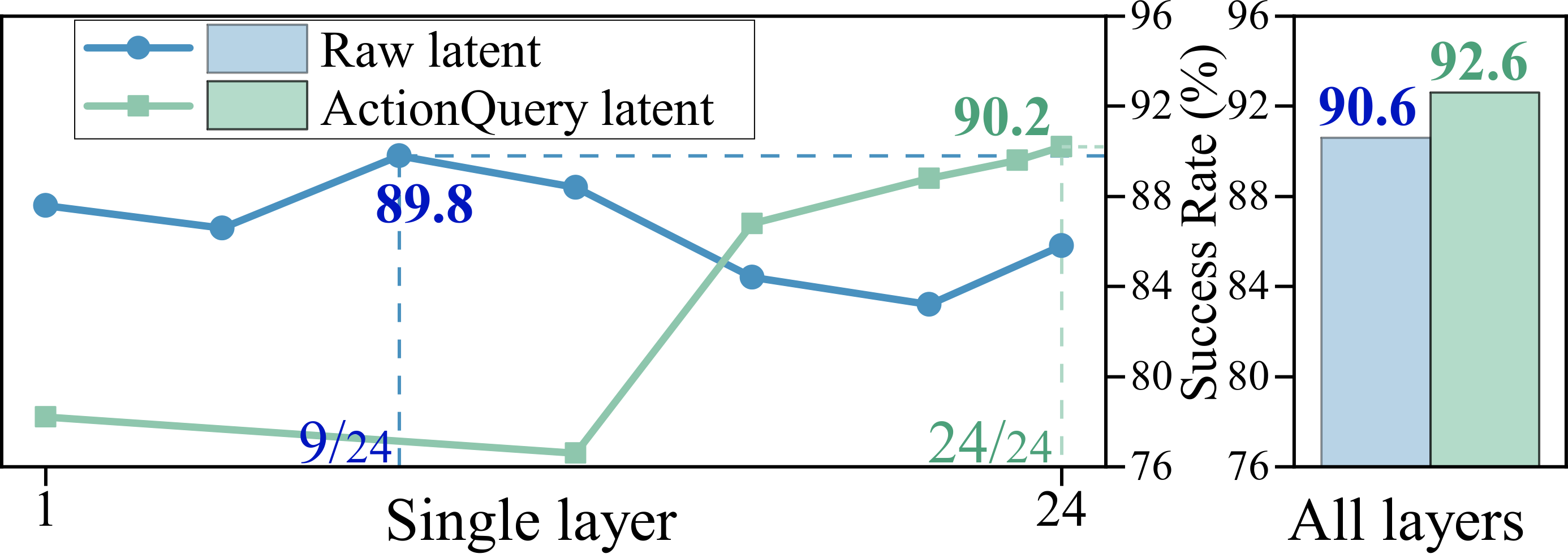
· Key Finding 3. Multi-layer features perform better. We observed that using all-layer features outperforms a single layer. Not only does it improve performance, but it also saves time on best layer selection during design.
· Key Finding 4. ActionQuery features generally outperform Raw features. The advantages of ActionQuery features are particularly evident when all layers are used, achieving a 2.0% higher success rate.
· Key Finding 5. Using too few ActionQuery weakens multimodal aggregation and makes it challenging to Policy. Conversely, using too many ActionQueries introduce redundancy, interfering with performance. We selected 64. It provides the balance between performance and efficiency.
· Key Finding 6. ActionQuery features can be fully injected, while Raw features require controlled injection. This result confirms that the injection degree in proposed Bridge Attention is effective.
- Question 2.1. What Are The Advantages of The VLA-Adapter Compared to Other Bridge Paradigms?
Effectiveness. To validate the effectiveness of our bridge paradigm, we compare three kinds of backbones: B1: Prismatic-VLMs (Qwen2.5-0.5B). B2: Prismatic-VLMs (LLaMA2-7B). B3: OpenVLA-7B. The first two are without pre-training on robotic data. We adopted the OpenVLA-OFT bridging way to compare.

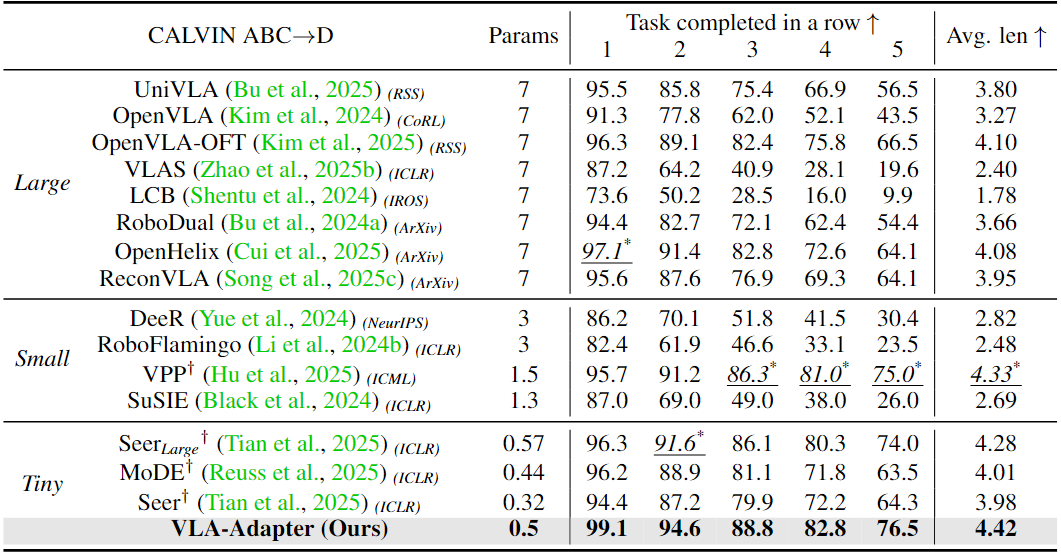
VLA-Adapter remains effective when the backbone is frozen. Only the ActionQuery and Policy are trained from scratch. SmolVLA is dedicated to studying frozen backbone. So, we compare with it and OpenVLA-OFT.

· Conclusion 1. VLA-Adapter improvement is obvious when VLMs without robotic pre-training.
· Conclusion 2. Even if the backbone freezes, VLA-Adapter still performs strongly.

We give two keyframe examples of the key frames of the robot arm performing a task. You can drag the progress bar in the middle bottom to view it.

Start RGB observation and Proprio. state

End RGB observation and Proprio. state

Start RGB observation and Proprio. state
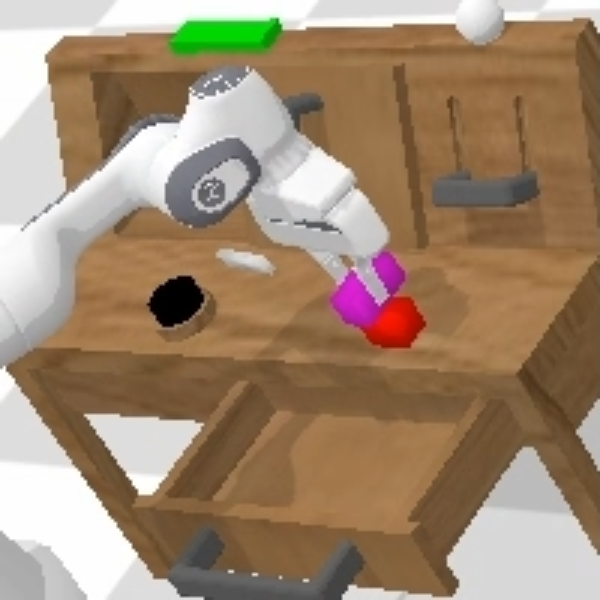
End RGB observation and Proprio. state
Fortunately, VLA-Adapter remains effective when the backbone is frozen. Only the ActionQuery latent and Policy are trained from scratch.
Instruction:
Put both the alphabet soup and the tomato sauce in the basket
@article{wang2025vlaadapter,
author={Wang, Yihao and Ding, Pengxiang and Li, Lingxiao and Cui, Can and Ge, Zirui and Tong, Xinyang and Song, Wenxuan and Zhao, Han and Zhao, Wei and Hou, Pengxu and Huang, Siteng and Tang, Yifan and Wang, Wenhui and Zhang, Ru and Liu, Jianyi and Wang, Donglin},
title={VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model},
journal={arXiv preprint arXiv:2509.09372},
year={2025}
}